Chapter 31: SIMD Part 1/3
The FPRs can be used as SIMD Vector Registers for parallel type fast operations. SIMD stands for Single Integer Multiple Data. Basically, SIMD means any instruction that can split data within a Register into groups of words/bytes/etc and operate on those groups in a parallel fashion. We refer to these groups as Lanes.
Instead of using the term "FPR", it is more proper to say "Vector Register". Values within the Vector Registers can be treated as floats or integers. The format of referencing a Vector Register within a Vector instruction is as follows (though some variances may apply)...
Vn.(1)(2)
V must be present as the first character. Optionally, you can use lowercase v.
n is the simply the Vector Register number, anything from 0 thru 31. You have 32 128-bit Vector Registers at your disposal.
(1)(2) options; fyi B,H,S, and D can be used as lowercase if desired:
As mentioned earlier, the value(s) within the Register(s) can be utilized as integers or as float values.
Example:
v12.2s = Vector Register 12 using a Vector of 2 lanes of word values
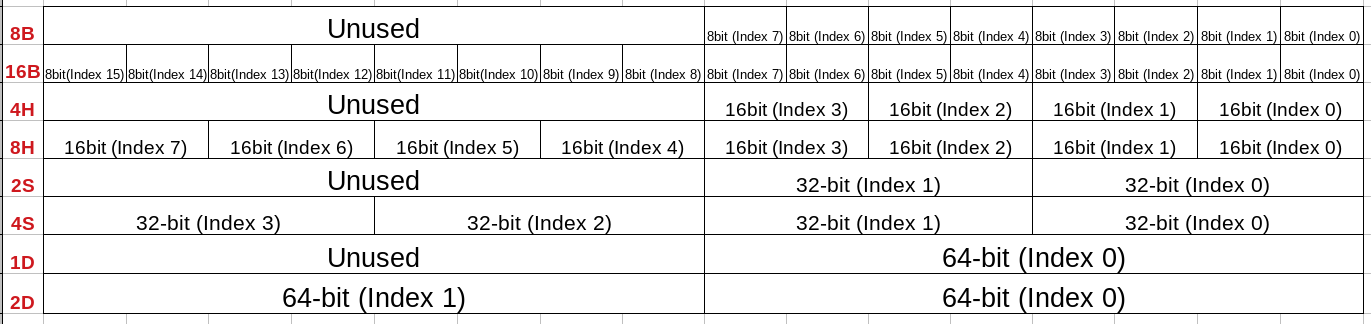
Here's a picture of all the possible various configurations ~
Notice how for each configuration, there is an index labeling arrangement. There are certain instructions where a certain index, or indices, can be selectively applied for said instruction.
For lane options that don't utilize the upper 64-bits, these are known as 64-bit Vectors. While the other lane options are called 128-bit Vectors due to utilizing all 128-bits of the Vector. Instructions that use 64-bit Vectors area known as 64-bit Vector Instructions.
IMPORTANT NOTE: For 64-bit vector instructions (unless otherwise specifically noted), the Destination Register will always have it's upper 64-bits set to null once said instruction has executed.
Since Vectors use the FPRs, to see the Vectors in GDB, you just issue the exact same command you would issue to see the FPRs...
info vector
Just like with Floats in the FPRs, to see the true/converted contents of the Vector, view its unsigned quadword value given by GDB.
Let's now dive into some instructions.
Some vector insertion aka move instructions:
ins Vd.<Td>[index], Vn.<Ts>[index2] @Copy vector index of source Vn into vector index of destination Vn. Vector configs for dest and source must match!
ins Vd.<Td>[index], Wn @Copy low 32-bits of GPR Wn into vector index of Vd. Vector config can be 8B, 16B, 4H, 8H, 2S, or 4S.
ins Vd.1D[index], Xn @Copy GPR Xn into vector index of Vd. only usable config is 1D.
NOTE: If desired, you can replace "ins" with "mov", for any of the 3 above insertion instructions. Note that GDB will choose to use mov over ins for the instruction naming.
Lets go over an ins/mov instruction to get a better idea.
mov v16.8H[7], w2
This instruction will....
Here's a pic in GDB of right before the instruction is going to execute..
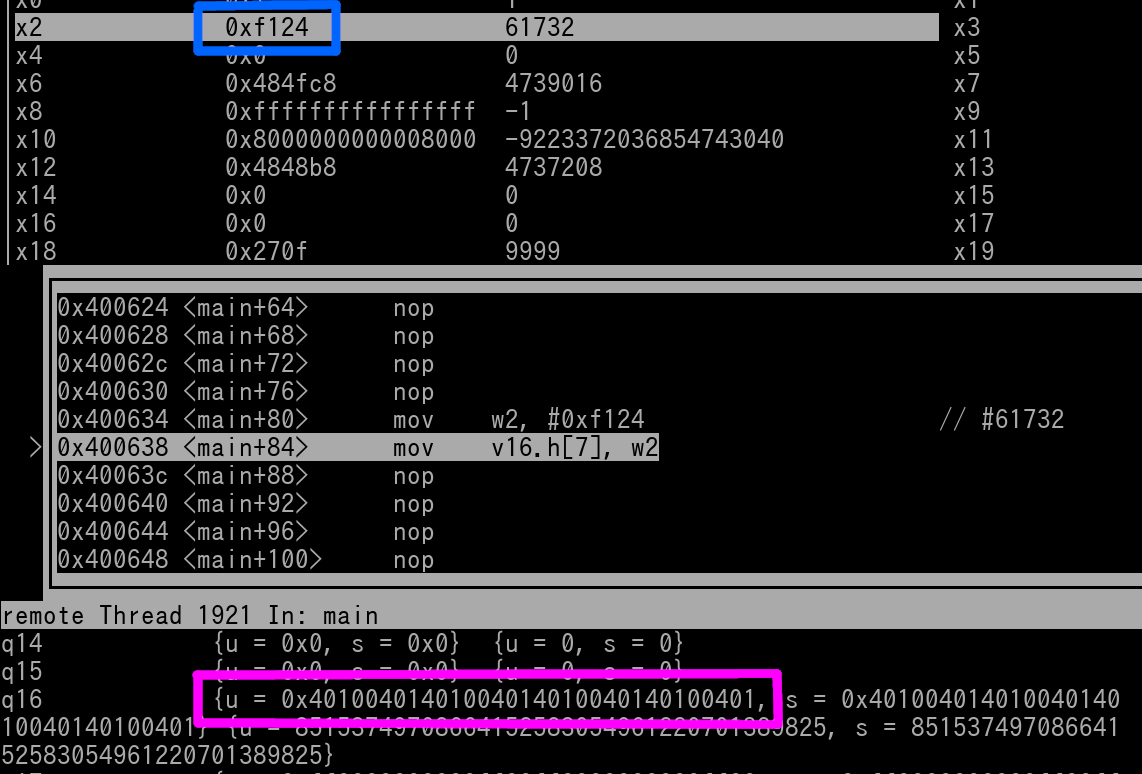
We see that the lower 16-bits of w2 is 0xF124, outlined in blue. We see that the current valid in v16 is 0x40100401401004014010040140100401, which is outlined in magenta.
Now here's a pic of once the instruction has executed.
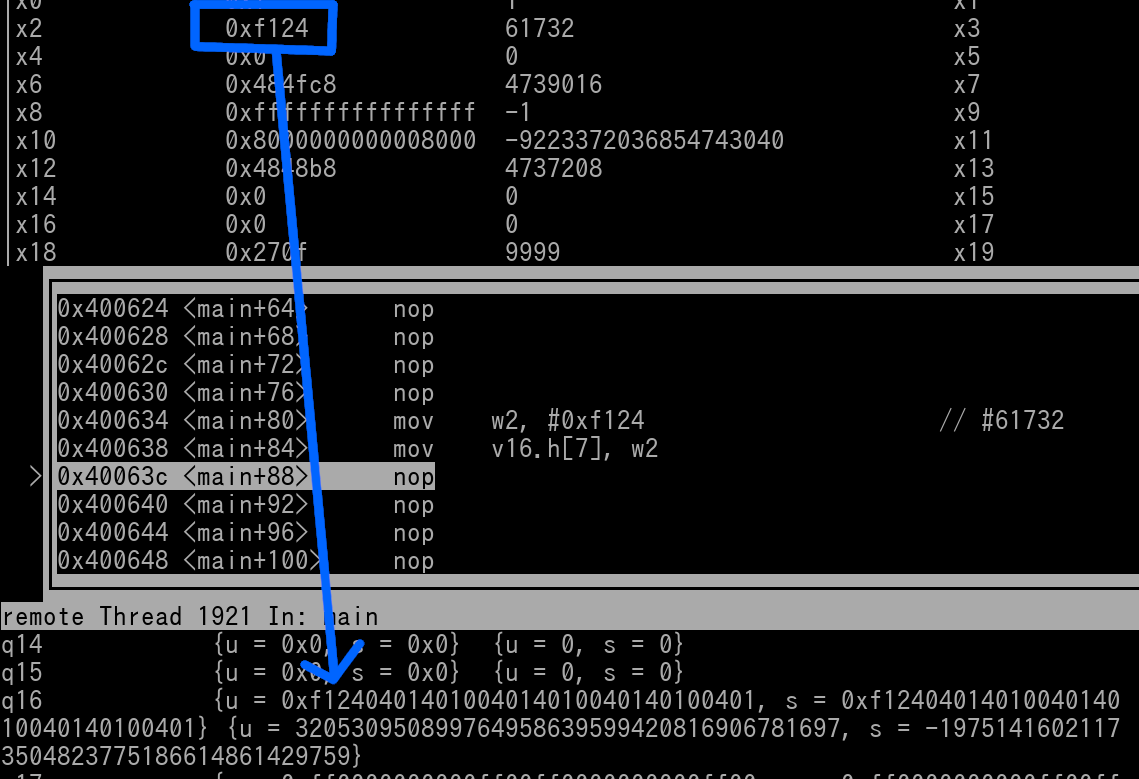
The 0x4010 beginning halfword value of the vector has been changed to 0xF124. Thus v16 is now 0xF1240401401004010040140100401.
The blue arrow shows how the halfword of w2 is copied into Lane 7 of v16.
Some vector duplication instructions:
dup Vd.<Td>, Vn.<Ts> [index] @Copy vector index from one FPR to to all indices of destination FPR. All vector configs can be used in this instruction. Vector Config for dest and source MUST match!
dup Vd.<Td>, Wn @Copy GPR register lower 32bit value to Vector FPR, usable configs are 8B, 16B, 4H, 8H, 2S, and 4S.
dup Vd.2D, Xn @Same as above but copies GPR whole 64 bits, only usable config is 2D
Let's go over a simple duplicate instruction in detail...
dup v4.4S, v10.4S[2]
The instruction will...
Here's a pic of v10 in GDB of right before the instruction is going to be executed.
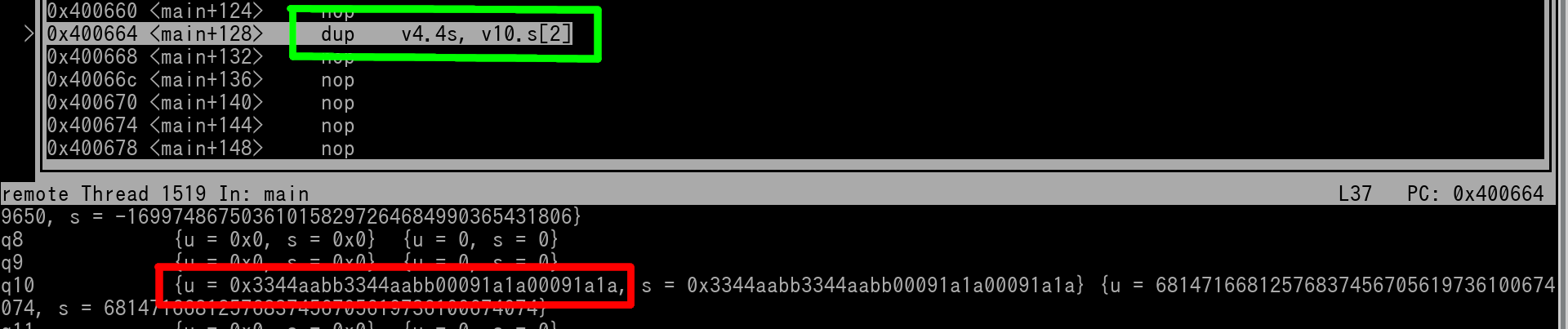
Instruction is outlined in green. We see that v10 (outlined in red) is 0x3344AABB 3344AABB 00091A1A 00091A1A. Thus it's index 2 value is 3344AABB.
Let's execute the instruction and see what has happened to v4.
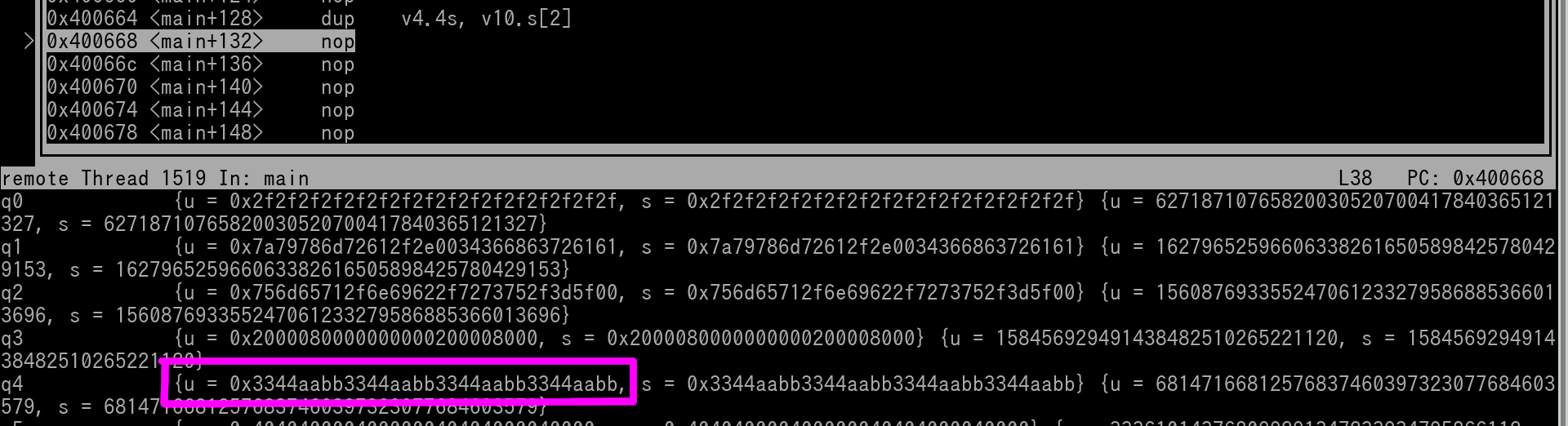
As you can see v4 has had v10's lane 2 (0x3344AABB) copied into all of its lane. Thus v4 is now 0x3344AABB 3344AABB 3344AABB 3344AABB. v4 is outlined in magenta.
--
You can use immediate values for directly loading a vector with a Floating Point Value. The range rules for fIMM is the same as a typical immediate fmov instruction.
Vector floating point move immediate instruction:
fmov Vd.<Td>, #fiMM @Vector format can be 2S, 4S, or 2D. VALUE is a decimal notation (i.e. 12.5). VALUE is loaded into all applicable lanes.
---
Here's a list of some basic Vector Integer Math instructions..
add Vd.<T>, Vn.<T>, Vm.<T> @Vector config can be 8B, 16B, 4H, 8H, 2S, 4S, or 2D. Vector N is added with Vector M. Result in Vector D.
mul Vd.<T>, Vn.<T>, Vm.<T> @Vector config can be 8B, 16B, 4H, 8H, 2S, 4S, or 2D. Vector N times Vector M = Vector D
sub Vd.<T>, Vn.<T>, Vm.<T> @Vector config can be 8B, 16B, 4H, 8H, 2S, 4S, or 2D. Vector N minus Vector M = Vector D
neg Vd.<T>, Vn.<T> @Vector config can be 8B, 16B, 4H, 8H, 2S, 4S, or 2D. Vector N is negated. Result in Vector D.
NOTE: div vector instruction does *not* exist
Let's go over the add instruction in particular.
Example:
add v20.4h, v15.4h, v20.4h
This will do the following...
Let's pretend...
Remember that 4 lanes of halfwords are being used, the upper 4 halfword lanes (upper 64-bits) of each Vector Register are ignored.
Here's pics of v15 and v20 right before the instruction is executed...
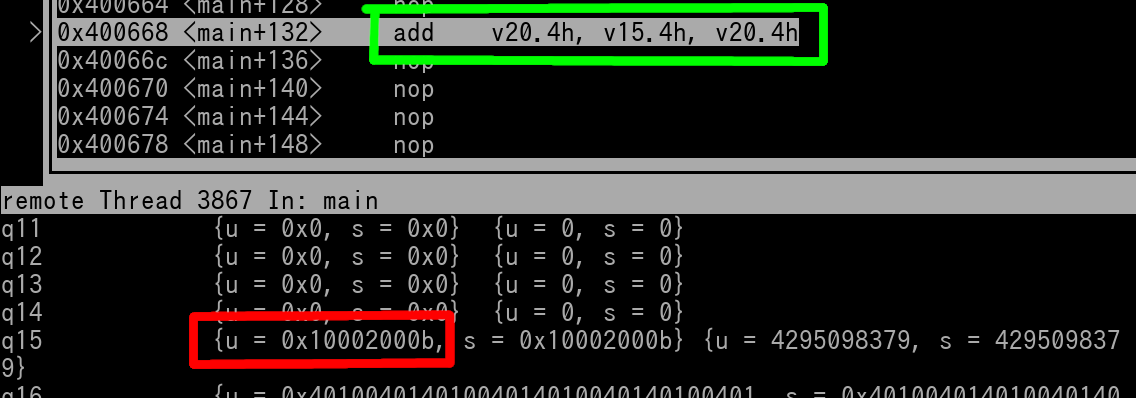
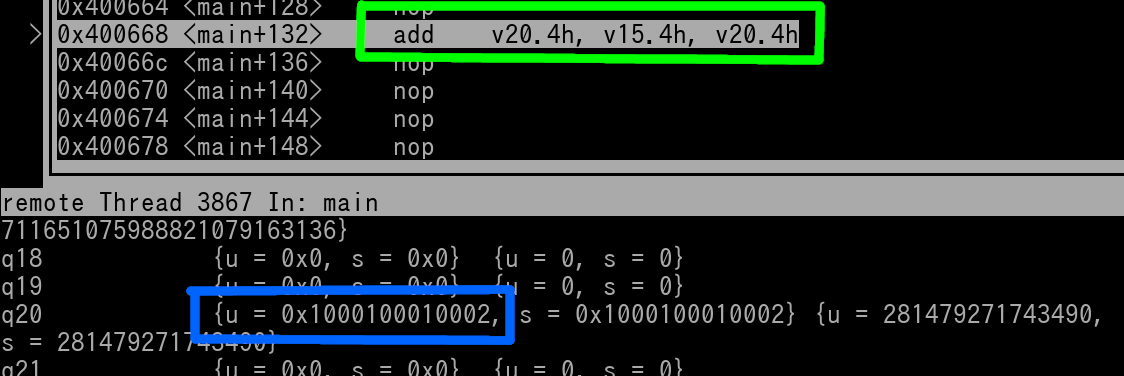
We see in the above pics that the add instruction is outlined green. v15 is outlined in red, and v20 is outlined in blue.
Here's a pic of v20 right after the instruction has executed...
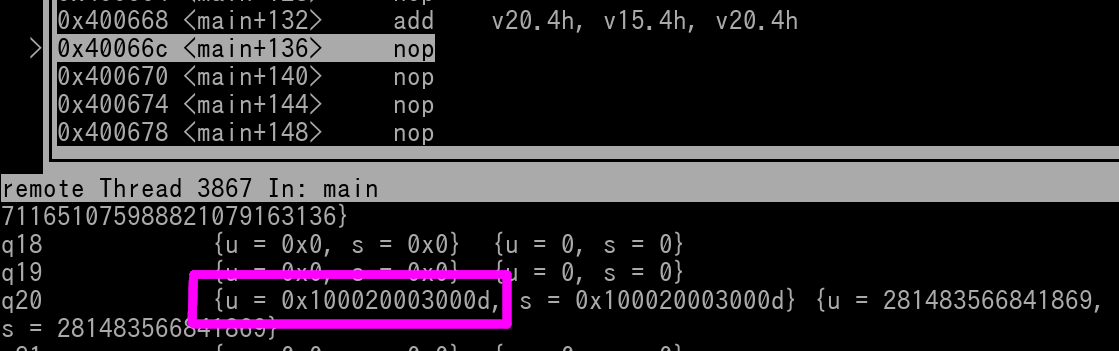
As you can see the result of v20 is now 0x000100020003000D. NOTE: If v20 did have non-zero data in it's upper 64-bits beforehand, the upper 64-bits are always set to null!
Here are some logical/bit operation based Vector Integer instructions...
and Vd.<T>, Vn.<T>, Vm.<T> @Vector config can be 8B, 16B. Vector N AND'd with Vector M. Result in Vector D.
orn Vd.<T>, Vn.<T>, Vm.<T> @Vector config can be 8B or 16B. Vector N is OR'd with the complement of Vector M. Result in Vector D.
orr Vd.<T>, Vn.<T>, Vm.<T> @Vector config can be 8B or 16B. Vector N OR'd with Vector M. Result in Vector D.
eor Vd.<T>, Vn.<T>, Vm.<T> @Vector config can be 8B or 16B. Vector N XOR'd with Vector M. Result in Vector D.
bic Vd.<T>, Vn.<T>, Vm.<T> @Vector config can be 8B or 16B. Vector N AND'd with the complement of Vector M. Result in Vector D.
not Vd.<T>, Vn.<T> @Vector config can be 8B or 16B. Vector N is NOT'd (NOR'd with itself). Result in Vector D.
We listed quite a bit of Integer based Vector instructions, here are some Floating Point Math Based Vector Instructions~
fadd Vd.<T>, Vn.<T>, Vm.<T> @Vector config can be 2S, 4S, or 2D
fmul Vd.<T>, Vn.<T>, Vm.<T> @Vector config can be 2S, 4S, or 2D
fsub Vd.<T>, Vn.<T>, Vm.<T> @Vector config can be 2S, 4S, or 2D
fdiv Vd.<T>, Vn.<T>, Vm.<T> @Vector config can be 2S, 4S, or 2D
fabs Vd.<T>, Vn.<T>, Vm.<T> @Vector config can be 2S, 4S, or 2D
fneg Vd.<T>, Vn.<T>, Vm.<T> @Vector config can be 2S, 4S, or 2D
Let's go over the fadd instruction in particular.
Example:
fadd v6.2s, v29.2s, v1.2s
This will...
Let's pretend...
Here's pics of v29 (outlined in red) and v1 (outlined in blue) right before the instruction (outlined in green) is executed...
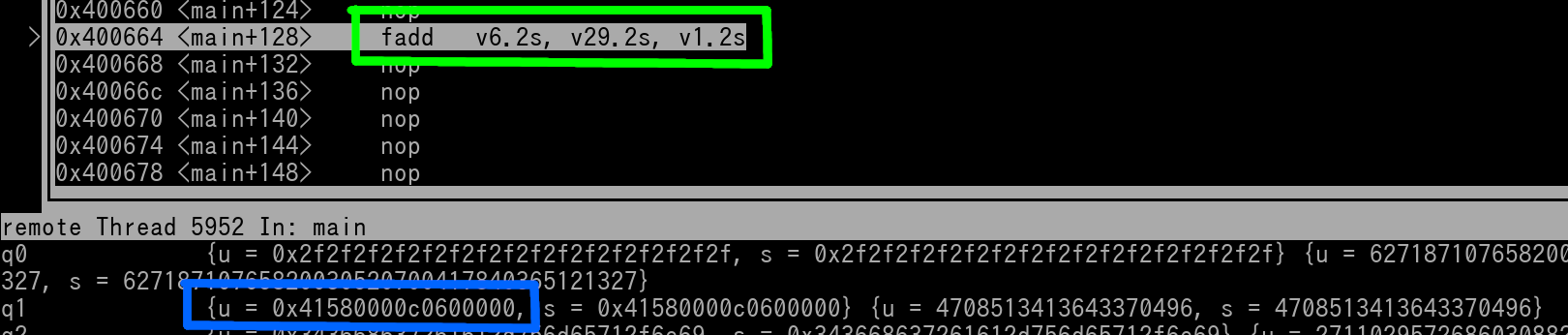
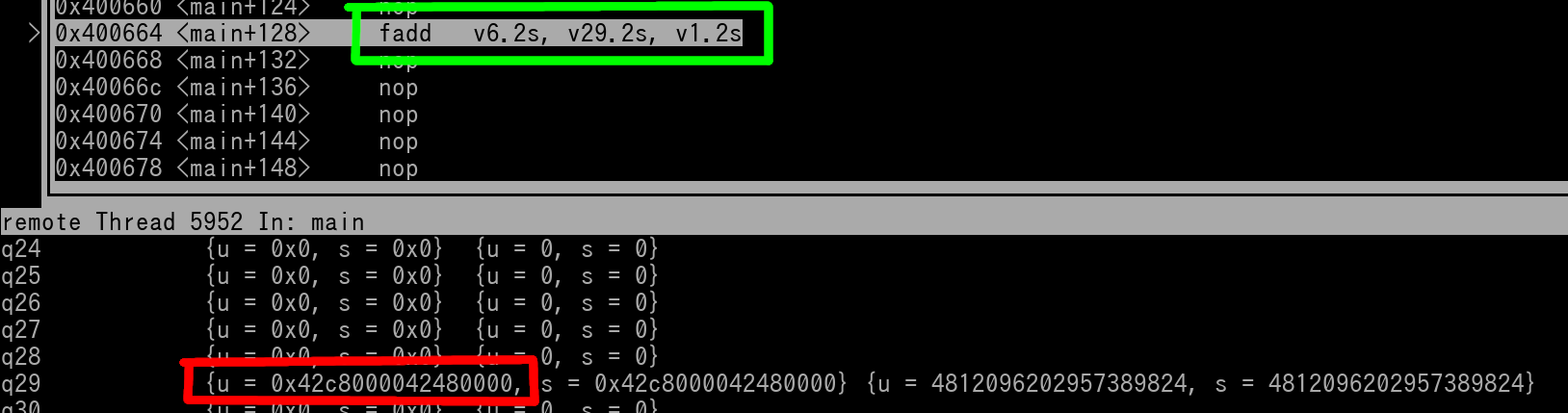
Here's a pic of v6 right after the instruction has executed...

As you can see, the result (outlined in magenta) is placed into v6. v6 is 0x42E30000 423A0000 because...
NOTE: The upper 64-bits of v6 are set to null by the fadd instruction. If there was any non-zero data in v6's upper 64-bits beforehand, it will always be nulled out because the instruction is a 64-bit vector instruction.
Other vector float instructions~
fmax Vd.<T>, Vn.<T>, Vm.<T> @Vector config can be 2S, 4S, or 2D
fmin Vd.<T>, Vn.<T>, Vm.<T> @Vector config can be 2S, 4S, or 2D
fsqrt Vd.<T>, Vn.<T>, Vm.<T> @Vector config can be 2S, 4S, or 2D. Square Root
frecpe Vd.<T>, Vn.<T>, Vm.<T> @Vector config can be 2S, 4S, or 2D. Reciprocal estimate
frsqrte Vd.<T>, Vn.<T>, Vm.<T> @Vector config can be 2S, 4S, or 2D. Reciprocal estimate of Square Root
NOTE: There are *no* fmadd, fmsub, fnmadd, fnmsub vector instructions!