Chapter 32: SIMD Part 2/3
Let's dive into some more complex SIMD instructions....
Vector Floating Point Add Pair~
faddp Vd.<T>, Vn.<T>, Vm.<T> @Vector config can be 2S, 4S, or 2D; values treated as floats
This is tough to explain so its best if we use an example.
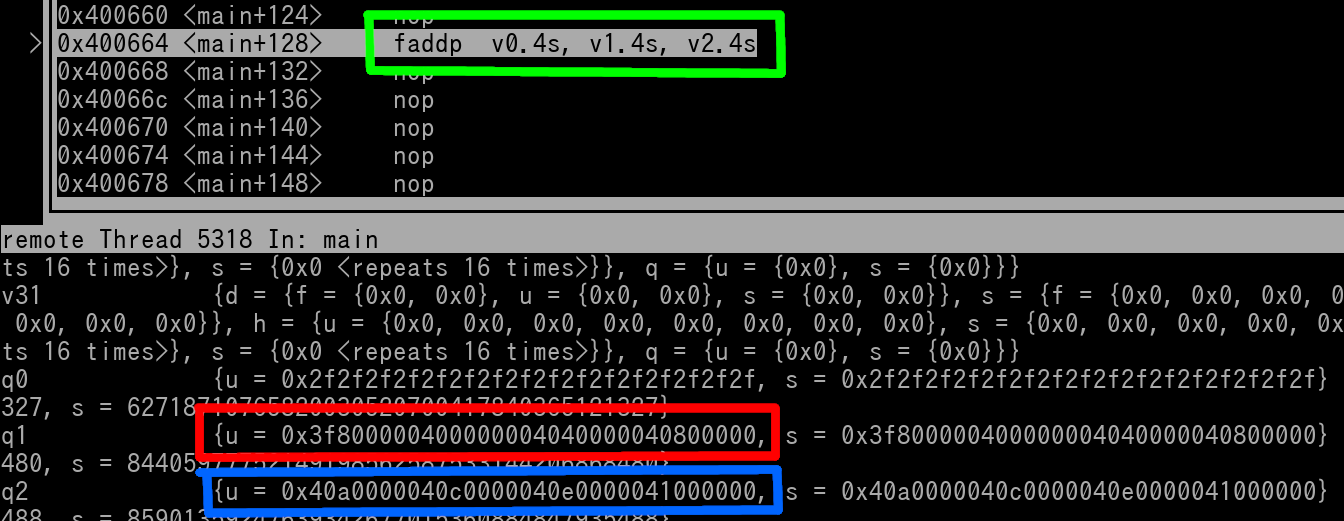
faddp v0.4s, v1.4s, v2.4s
We can see that we are working on 4 lanes of single precision floats. Let's say the source registers (v1 and v2) are the following values...
v1 = 0x3F800000 40000000 40400000 40800000
v2 = 0x40A00000 40C00000 40E00000 41000000
In decimal form the values are...
v1 = 1, 2, 3, 4
v2 = 5, 6, 7, 8
The faddp instruction preforms the following..
Thus the following results occur...
5 + 6 = 11 (v0 Lane 3; far left lane)
7 + 8 = 15 (v0 Lane 2; middle left lane)
1 + 2 = 3 (v0 Lane 1; middle right lane)
3 + 4 = 7 (v0 Lane 0; far right lane)
The 2nd Source Register (v2) has its paired additions placed into the two lefthand slots of the Destination Register (v0)
The 1st Source Register (v1) has its paired additions placed into the two righthand slots of the Destination Register (v0)
In conclusion v0 will contain the following result...
0x41300000 41700000 40400000 40E00000
Let's look at this in GDB. Here's a pic of right before the instruction has executed. v1 is outlined in red. v2 is outlined in blue. Instruction is outlined in green.
Now let's execute the instruction...
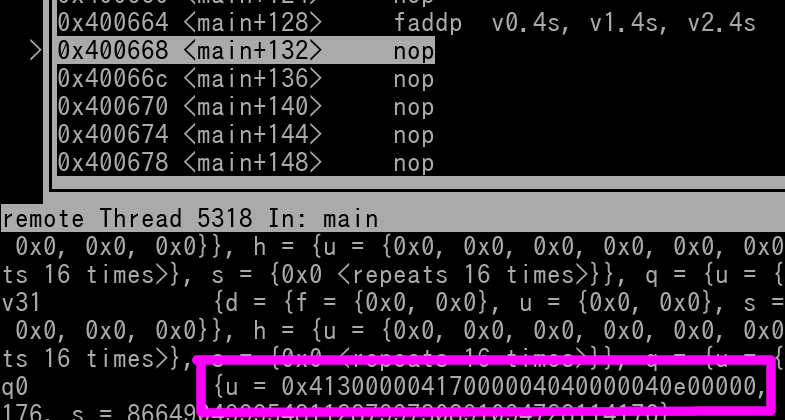
We can see that v0 (outlined in magenta) does indeed contain the result of 0x41300000 41700000 40400000 40E00000.
The faddp instruction can be vary useful for math equations, such as Pythagorean Theorem. Fyi, an integer form of this instruction exists (addp).
Vector Integer Add Pair~
addp Vd.<T>, Vn.<T>, Vm.<T> //Vector config can be 8B, 16B, 4H, 8H, 2S, 4S, or 2D.
addp does the same as the above faddp except the addition operations are preformed as integers instead of floating points.
Let's cover another add pair based instruction. That will be the scalar version of faddp.
faddp <V>d, Vn.<T> //V and T respective vector config can be S/2S, or D/2D
This takes the input as a vector (2 lanes of single or double precision floats) and the output will be a regular plain jane floating point result (single or double precision lane 0). The upper 96 bits of the Destination Register in the s/2s version of the instruction will always be set to null. The upper 64 bits of the Destination Register in the d/2d version of the instruction will always be set to null.
Let's look at an example.
faddp s0, v0.2s
v0's value before instruction will be 0x41300000 41700000 40400000 40E00000
The instruction will...
Single precision float values of v0 Lane 1 + v0 Lane 0 = v0 (lane 0)
Thus the following addition is preformed
3 + 7 = 10 = Lane 0 of v0
Here's a picture of right before the instruction is executed...
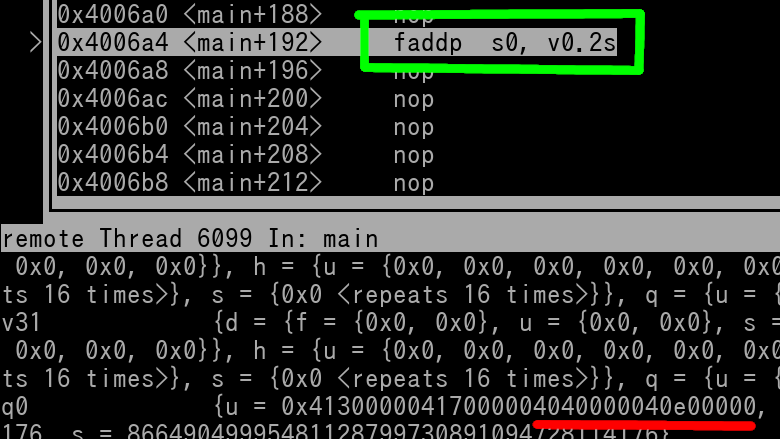
We can see the instruction is outlined in green. v0's Lanes 1 & 0 are underlined in red.
Now here's a picture of once the instruction has executed....
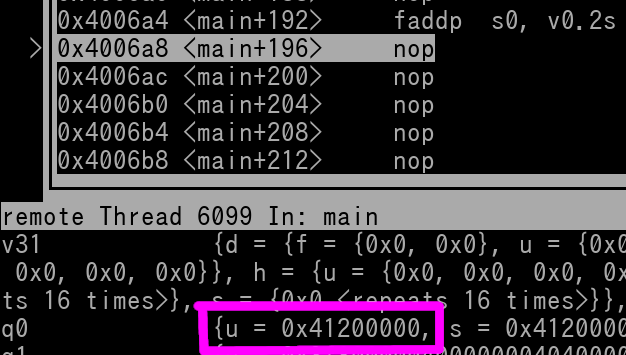
Our result (v0; outlined in magenta) is 0x41200000 (upper 96 bits are null)
Fyi, there's an Integer version of this...
addp Dd, Vn.2D @Vector config can *only* be D/2D. Values treated as Integers.
Moving on to some more complex stuff in SIMD....
Example vector element integer instruction:
mul Vd.<T>, Vn.<T>, Vm.<Ts>[index]
//This will take the value that's in Vector M's designated indexed lane and use said value to multiply every lane value of Vector N. Result of this multiplication goes into Vector D. Vector config (T/Ts respectively) can be 4H/H, 8H/H, 2S/S, or 4S/S. If Ts = H, then Vector M cannot use an FPR higher than FPR 15.
Example vector element float instruction:
fmul Vd.<T>, Vn.<T>, Vm.<Ts>[index]
//Same exact operation as the above mul instruction, but values are now treated as floating points. Vector config (T/Ts respectively) can be 2S/S, 4S/S, or 2D/D. If Ts = S, then Vector M cannot be use an FPR higher than FPR 15.
I briefly want to mention one more type of SIMD instruction before move on to the next Chapter. As an fyi, you are not required in certain instructions to keep the same "width" of lanes during vector operations. There are 3 terms used for each diff type of change of vector width.
Keep in mind that these type of vector instructions can only be done for integer value within the FPRs. In conclusion, there's even more stuff about SIMD I didn't cover, be sure to read up on Chapter 5.7 of the Instruction Overview pdf for more info and examples.