Chapter 29: Cache Part 2/2
Before we can dive into actual Cache instructions, you need to know about the 3 different Domains that are to specified within any System. Since a System can have a multiple processors, and each processor can have multiple cores, this creates different types of "domains" within said system.
There are 3 types of domains....
Unfortunately, what items (agents) that are covered within each Domain is entirely dependent on the configuration of the System. Not only that, there are conflicting diagrams on the internet! So this can get really really confusing.
Let's start from "inside" the System and work outward.
A core is the most basic agent in a system. The core is responsible for the actual execution of instructions (that is read from memory). Each Core contains...
For damn near all Systems, the term Non-Shareable refers to the individual Core only.
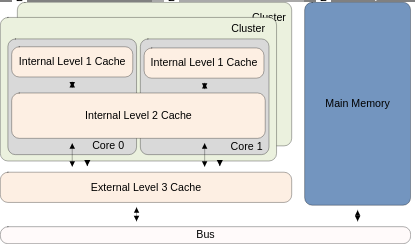
A processor can contain a single core or multiple cores. Thus you can have multiple cores running different code from a single program at the same time. This is known as Multi Threading. Nowadays, damn near all processors contain multiple cores. Let's say a processor contains 4 cores. The cores can be split into 2 pairs of 2. Each pair of cores can then share their own L2 Cache that connects them. This pair of Cores is known as a Cluster.
For some cases, the term Inner-Shareable refers to a Cluster. While other cases the term Inner-Shareable refers to *all* processors in the System.
Moving further outward, all Clusters can then share a single L3 Cache. Thus, if the system is a Multi Processor system, each Processor contains a single L3 Cache.
Main (Physical) Memory is the memory that will then be shared between all processors. The System will also contain other agents such as a GPU, DSP, I/O Chip, etc.
For most cases the term Outer-Shareable refers to the entire System as a whole.
Here's a generic diagram of a Processor...
Notice that each Core has its own L1 Cache units. The cores are broken up into Clusters and each Cluster shares their own L2 Cache. Finally all clusters are sharing a single L3 Cache.
An agent known as the Bus is what connects the Processor to Physical Memory. In the previous Chapter, we talked about Cache Hits vs Misses. The diagram shows how a Cache Miss degrades performance. In the case of a Cache Miss, the Processor has to check L1 Cache, then move "out" to check L2, then move "out" to check L3, and then finally move "out" to check Physical Memory.
The Nintendo Switch's System is a bit weird. It contains a Single Processor (Cortex A-57) that has 4 cores. The 4 cores are *not* split into 2 clusters. There is only 1 cluster. All 4 cores share a single L2 (Data-only) Cache. There is *NO* L3 Cache in this System.
For the Switch's system, the domains are as follows..
Diagram of the Switch's Processor~

Finally, with all of that out of the way, here are all the ARM64 cache instructions...
It's important to note when using a Virtual Address in a cache instruction, you do *NOT* need to have the address 64-byte aligned for the instruction (for the case of the Cortex A-57 which uses 64-byte Cache Blocks/Lines). The CPU will auto align the address to 64-bytes and the 64 bytes at that aligned address will be effected by the cache instruction.
Data Cache Instructions~
Instruction Cache Instructions~
Xd = Memory Address
Xt = Integer Value/flags to specify the Set or Way.
Some of the instructions mention "Point of Coherency" and "Point of Unification". What do these terms mean?
Point of Coherency aka PoC = The cache updates are pushed to Physical Memory. Therefore all Cores, DSPs, I/O devices, DMA engines, etc all see the same copy of Memory.
Point of Unification aka PoU = The cache updates only occur on the working core in question, nowhere else.
The Data Cache state bits can be a bit complex to understand. Obviously something like a data cache invalidate instruction will set the Cache block to Invalid. However for other data cache instructions, it's best if I explain what occurs in a general overview.
Not only that some of the descriptions of the instructions are tailored to be specific for the Cortex A-57.
dc zva = This will zero out a block/line of Cache (virtual cached memory). After some time, the zeroed contents will be written to Physical memory. It's important to know that the zeroed contents are not guaranteed to end up in Physical Memory due to the possibility of another Core having its L1 Data Cache already containing the same block that's in the M bit state. Because of this uncertainty, if this instruction is used, you must be a barrier instruction afterwards (more on this in next Chapter).
dc ivac = This simply invalidates the Cache Block/Line. It effects all Cores of the System. Any contents residing in Cache that was going to be written to Physical Memory will be discarded.
dc isw = Similar mechanism as ivac but for sets/ways. You can mark an entire Set or Way as Invalid. This is done certain bit flags in the Destination Register being used. You have to choose which Level of Data Cache is effected. L1 (working core), L2 (working cluster/processor), etc. PoU vs PoC doesn't apply here.
dc cvac = This will force the Cached contents to be written to Physical Memory. It effects all Cores in the System. Thus complete coherency (Virtual Cached memory matching Physical Memory) on this Data Cache Block is achieved for the entire System.
dc csw = Similar mechanism to cvac but for Sets/Ways. You can mark an entire Set or Way as clean. This is done via certain bit flags in the Destination Register being used. You have to choose which Level of Data Cache is effected. L1 (working core), L2 (working cluster/processor), or L3 (working processor). PoU vs PoC doesn't apply here. Instruction doesn't broadcast.
dc cvau = This will force the L1 D-Cache, and other Memory Units (i.e. TLB) of the working Core to see the same specific Cache Block (same block of Virtual Cached Memory). Thus the L2 Cache will also be updated with the same Block contents. Other Cores' L1 D-Caches and Memory Units are ***not*** updated. However, the other Cores' agents can be updated if a barrier instruction is used afterwards (more on Barrier instructions in Next Chapter).
dc civac = Will first execute a dc cvac instruction but then will set the Block (in all Cores) to be Invalid.
dc cisw = Same mechanism as civac but for sets/ways. You can clean then invalidate an entire Set or Way. This is done certain bit flags in the Destination Register being used. You have to choose which Level of Data Cache is effected. L1 (working core), L2 (working cluster/processor), or L3 (working processor). PoU vs PoC doesn't apply here. Instruction doesn't broadcast.
ic ialluis = Set every block in all instruction cache units in the inner shareable domain to be tagged Invalid.
ic iallu = Invalidates the entire L1 I-Cache of the working Core only.
ic ivau = Same as above but this only effects the specific I-Cache block designated by the given Address.
If you are ever in a situation where you have contents present in Virtual Memory (from a previous store), you can ensure it will be in Physical Memory by issuing a dc cvac instruction using the Address of the contents in question. Remember, for something like the Cortex A-57, Cache blocks are 64-byte aligned (64 byte sizes). Keep that in mind if contents expand across two 64-byte aligned regions of memory.
You can use the dc zva instruction to quickly zero out a large region of memory if necessary. Just remember that Virtual Memory is only effected immediately.
If there is something in the cache that you don't want to ever reach Physical Memory, issue a dc ivac instruction for it.